
To study and perform the Find-S algorithm for hypothesis learning
Introduction
The Find-S algorithm, developed by Tom Mitchell, is a pivotal machine learning algorithm for supervised concept learning and hypothesis space exploration. The algorithm is designed to find a maximally specific hypothesis that fits all the positive examples, while ignoring negative examples during the learning process. The algorithm's ultimate goal is to discover a hypothesis that accurately represents the target concept by progressively expanding the hypothesis space until it covers all positive instances.
Notation used in Find-S Algorithm
- 'ϕ' indicates that no value is acceptable for the attributes.
- '?' indicates that any value can be acceptable for the attributes.
- The most specific hypothesis is represented by {ϕ, ϕ, ϕ, ϕ} where number of the 'ϕ' is equal to number of attributes in training data set.
- The most general hypothesis is represented by {?, ?, ?, ?} where number of the '?' is equal to number of attributes in training data set.
Algorithm
Input: Set of positive training examples D
Output: Hypothesis h
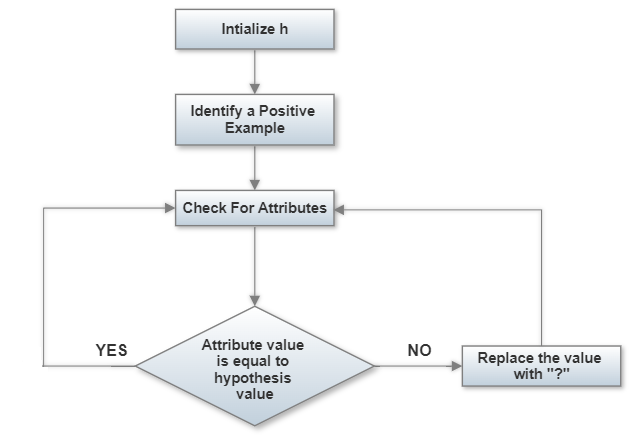
Step 1: Initialize h to the most specific hypothesis in the hypothesis space.
Step 2: For each positive training example x in D:
for each attribute’s constraint ai in h:
if the constraint ai is satisfied by x
then do nothing
else
replace ai in h by the next general hypotheses Constraint ‘?’ that is satisfied by x.
Step 3: Return the hypothesis h.
Limitations of Find-S Algorithm
- There is no way to determine if the hypothesis is consistent throughout the data.
- Inconsistent training sets can actually mislead the Find-S algorithm, since it ignores the negative examples.
- Find-S algorithm does not provide a backtracking technique to determine the best possible changes that could be done to improve the resulting hypothesis.
- For larger datasets or higher-dimensional spaces, the algorithm's efficiency can decrease as it needs to iterate through each attribute for each positive example.