
To study and perform Naive-Bayes Classifier for Document Classification
Introduction
Naive Bayes is a simple but powerful probabilistic algorithm used for classification tasks, including document classification. It's based on Bayes' theorem, which calculates the probability of a hypothesis (class label) given the evidence (features). In document classification, the goal is to assign a category or label to a document based on its content. Naive Bayes assumes that the presence or absence of each word or term in the document is independent of the presence or absence of other words, hence the term "naive". Although this assumption is often violated in real-world scenarios, Naive Bayes can still perform surprisingly well in practice, especially for text classification tasks, including document categorization, sentiment analysis, and spam detection.

Working of Naive Bayes for Document Classification:
Training :
- First, you need a labeled dataset containing documents along with their corresponding categories or labels.
- From this dataset, Naive Bayes calculates the probabilities of each class (category) and the probabilities of each term occurring in each class.
Preprocessing :
- Before training, the text data usually undergoes preprocessing steps like tokenization (splitting text into words or terms), removing stop words (commonly occurring words like "the", "is", "and", etc.), and stemming (reducing words to their root form, like "running" to "run").
Calculating Class Probabilities : For a given document, Naive Bayes calculates the probability of each class given the document's terms using Bayes' theorem:
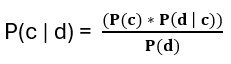
- P(c∣d) is the probability of class c given the document d.
- P(c) is the prior probability of class c, which is the proportion of documents in the training set that belong to class c.
- P(d∣c) is the likelihood, the probability of observing the document d given class c. It's calculated as the product of the probabilities of each term in the document given class c.
- P(d) is the total probability of observing the document, which is the same for all classes and can be ignored in practice because it's just a scaling factor.
Fig. 2 Bayesian Model
Predicting Class : Once the probabilities for each class are calculated, the class with the highest probability is assigned to the document.
Smoothing : To handle the issue of zero probabilities (i.e., when a term in a test document doesn't occur in the training data for a particular class), smoothing techniques like Laplace smoothing or Lidstone smoothing are often applied.
The formula for Laplace smoothing is as follows:
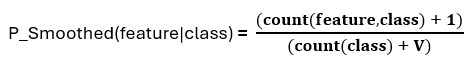
P_smoothed(feature|class) = smoothed conditional probability of the feature given the class,
count(feature,class) = count of occurrences of the feature with the specific class in the training data,
count(class) = count of occurrences of the class in the training data,
V = number of unique feature values for the given feature.
- Evaluation : After training, the performance of the classifier is evaluated using a separate test dataset, typically using metrics like accuracy, precision, recall, and F1-score.
Advantages
- Simple and Efficient : Naive-Bayes classifiers are computationally efficient and can handle large-scale datasets with ease, making them suitable for real-world applications.
- Assumption of Feature Independence : Despite its oversimplified assumption of feature independence, Naive-Bayes often performs well in practice, especially in situations where this assumption holds approximately true.
- Scalability : Due to its computational efficiency and low memory requirements, Naive-Bayes classifiers can be easily scaled to handle large volumes of textual data.
- Effective with High-Dimensional Data : Naive-Bayes classifiers perform well in high-dimensional spaces, such as those encountered in text classification tasks where the number of features (words) can be substantial.
Disadvantages
- Assumption of Feature Independence : One of the fundamental assumptions of the Naive-Bayes classifier is the independence of features, meaning that it assumes that the presence of one feature is independent of the presence of other features. In practice, this assumption may not hold true for all datasets, leading to potential inaccuracies in classification.
- Zero Frequency Problem : In situations where a feature does not appear in the training data for a particular class, the Naive-Bayes classifier assigns a probability of zero to that feature. This can cause issues during classification, as it effectively eliminates the influence of other features, even if they are relevant.
- Data Imbalance : Naive-Bayes classifiers may struggle with imbalanced datasets, where one class significantly outnumbers the others. Since they rely on the relative frequencies of features in each class, imbalanced datasets can lead to biased probability estimates and poor classification performance.
- Sensitive to Irrelevant Features : Naive-Bayes classifiers can be sensitive to irrelevant features or noise in the data. Since it treats features as independent, the presence of irrelevant features can influence the classification decision, leading to reduced accuracy.
Applications
- Spam Detection : Naive-Bayes classifiers are effective in distinguishing between spam and non-spam emails based on the presence or absence of certain keywords or features.
- Topic Categorization : They can classify news articles, research papers, or blog posts into predefined topics or categories, such as sports, politics, technology, etc.
- Sentiment Analysis : Naive-Bayes classifiers can determine the sentiment (positive, negative, neutral) expressed in user reviews, social media posts, or customer feedback.
- Language Identification : They can identify the language of a document based on its textual content, which is useful in multilingual environments.