
To study and implement the working of an Artificial Neural Network
Introduction
Artificial Neural Networks (ANNs) are computational models inspired by the structure and functionality of the human brain. These networks have gained significant attention and popularity due to their ability to learn patterns from data and make predictions. ANNs are widely used in various fields, including computer vision, natural language processing, robotics, finance, and more.
The architecture of a neural network refers to its overall structure and organization, including the arrangement of its layers and the number of nodes in each layer. The network architecture plays a crucial role in determining the network's capacity to learn complex patterns and make accurate predictions.
A typical neural network consists of three main types of layers : the input layer, hidden layer(s), and the output layer.
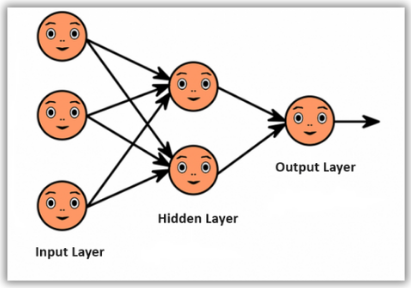
Artificial neurons vs Biological neurons
The concept of artificial neural networks comes from biological neurons found in human brains, so they share a lot of similarities in structure and function. The structure of artificial neural networks is inspired by biological neurons. A biological neuron has a cell body or soma to process the impulses, dendrites to receive them, and an axon that transfers them to other neurons. The input nodes of artificial neural networks receive input signals, the hidden layer nodes compute these input signals, and the output layer nodes compute the final output by processing the hidden layer’s results using activation functions.
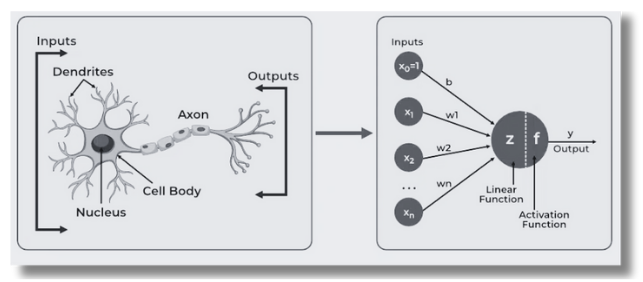
Main components of ANN:
- Input Layer:
The input layer is the initial layer of a neural network and serves as the entry point for external data. This layer receives the raw information or features from the dataset and passes them through to the subsequent layers for processing. Key characteristics of the input layer are:
- Nodes/Neurons : Each node in the input layer represents a feature or attribute from the input data. For instance, in an image recognition task, each node might correspond to a pixel in the image, or in natural language processing, each node could represent a word in a sentence.
- No Computation : The input layer does not perform any computation. Its primary function is to transmit the raw input data to the network.
- Dimensionality : The number of nodes in the input layer is determined by the dimensionality of the input data. If the input is an image with dimensions of 32x32 pixels, the input layer would have 32*32 = 1024 nodes.
- Normalization : Sometimes, preprocessing steps like normalization are applied at the input layer to ensure that the input data is standardized, making it easier for the neural network to learn.
- Hidden Layer:
The hidden layer in a neural network is an intermediate layer situated between the input layer and the output layer. The hidden layer(s) processes the information from the input and contributes to the network's ability to learn and generalize. Here are some key points about hidden layers:
- Nodes/Neurons : Each node in a hidden layer represents a learned feature or abstraction derived from the input data. The number of nodes in a hidden layer is a parameter that can be adjusted based on the complexity of the task and the characteristics of the data.
- Computation : The nodes in a hidden layer perform computations. Each node receives input from the nodes in the previous layer (either the input layer or another hidden layer), applies a weighted sum, and passes the result through an activation function. This introduces non-linearity to the network, allowing it to learn complex relationships in the data.
- Activation Functions : Activation functions, such as sigmoid, tanh, or rectified linear unit (ReLU), are applied to the output of each node in the hidden layer. These functions determine whether a neuron should be activated or not based on the weighted sum of its inputs. These functions introduce non-linearities, enabling the neural network to model more complex relationships in the data.
- Feature Learning : The hidden layers are crucial for feature learning and abstraction. As the network undergoes training, the weights of connections between nodes are adjusted to capture relevant patterns and relationships in the input data. The hidden layers act as hierarchical feature extractors, learning increasingly abstract representations of the input.
- Depth and Width : The depth and width of the hidden layers impact the network's capacity to learn and generalize. A deeper network with more hidden layers can potentially capture more complex features, while increasing the width (number of nodes) in a layer can provide more representational power.
- Output Layer:
The output layer is the final layer in a neural network, responsible for producing the network's predictions or outputs based on the information processed through the preceding layers. The structure and function of the output layer depend on the nature of the task the neural network is designed to solve, and it is often tailored to match the specific requirements of that task. Here are key aspects of the output layer:
- Nodes/Neurons : The number of nodes in the output layer corresponds to the number of classes or dimensions in the target variable for the given task. For instance, in a binary classification task, there may be one output node for each class (e.g., class 0 and class 1). In a multiclass classification task, there would be as many nodes as there are classes.
- Computation : Each node in the output layer performs computations based on the information received from the nodes in the preceding layer (usually the last hidden layer). The computations typically involve weighted sums of inputs, and the result is often passed through an activation function. The choice of activation function in the output layer depends on the nature of the task.
- Activation Functions : The choice of activation function in the output layer is task-specific. For binary classification, a sigmoid activation function is commonly used, producing a probability-like output and for multiclass classification, a softmax activation function is often employed. It converts the raw output scores into probability distributions across multiple classes, ensuring that the sum of probabilities equals 1.
- Loss Function : It quantifies the difference between the predicted output of the network and the actual target values. The goal during training is to minimize this loss, as doing so leads to a more accurate and effective neural network. The choice of the loss function is tied to the task and the activation function in the output layer.
- Regression Models : predict continuous values.
- Mean Squared Error (MSE)
- Mean Absolute Error (MAE)
- Mean Bias Error (MBE)
MSE = (1/n) * Σ(yᵢ - ȳᵢ)² MAE = (1/n) * Σ|yᵢ - ȳᵢ| MBE = (1/n) * Σ(yᵢ - ȳᵢ) - Classification Models : predict the output from a set of finite categorical values.
-
Cross-Entropy Loss
Cross-Entropy Loss = -[yᵢ * log(ȳᵢ) + (1 - yᵢ) * log(1 - ȳᵢ)] where,
i - ith training sample in a dataset,
n - number of training samples,
yᵢ - Actual output of ith training sample,
ȳᵢ - Predicted value of ith training sample.
-
Cross-Entropy Loss
- Interpretation of Output : The output layer's values or probabilities represent the network's prediction for each class. During training, the network adjusts its weights to minimize the difference between these predictions and the actual target values.
Loss functions are classified into two classes based on the type of learning task:
- Weight:
- Neural network weights are numerical values representing connection strength between nodes. They determine the impact of one node's output on another.
- The goal is to find weights minimizing the difference between predicted and actual outputs.
- The learning rate, affecting model convergence, determines the step size of weight updates.
- Weights can be positive or negative, indicating whether a connection has a positive or negative impact on the receiving node's activation.
- Larger weights amplify influence, while smaller weights attenuate it. Adjusting weights allows the network to assign varying importance levels to information, facilitating learning and pattern adaptation.
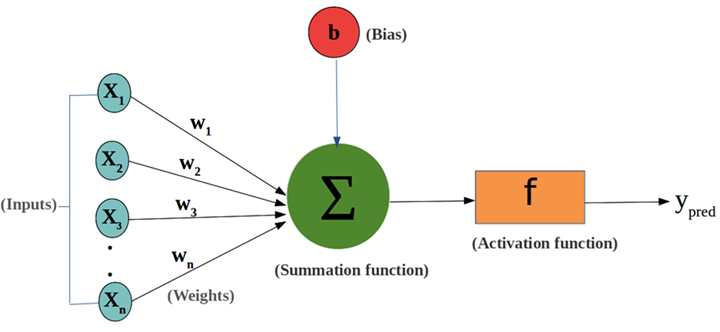
Bias:
- Biases are constant values associated with each node in a neural network, including the input, hidden, and output nodes. Bias nodes introduce a level of flexibility and enable the network to learn and adapt to different situations.
- Each bias node has its own associated bias value, which is conceptually similar to a weight. However, unlike weights, biases do not depend on any input; they provide a constant value that is added to the weighted sum of inputs of a node.
- By adjusting the biases, the network can be fine-tuned to better fit the training data and generalize well to unseen data. Like weights, biases are updated during the training process to minimize the difference between predicted and actual outputs, making the network more accurate and robust.
Activation function:
Activation functions aid neural networks in tackling complex tasks, like distinguishing between cats and dogs, by enabling them to grasp non-linear concepts. Neurons use activation functions to decide whether to activate based on weighted input sums. If the sum exceeds a threshold, the neuron activates, passing output to the next layer. The main role of activation functions is to introduce non-linearity, crucial for the network to learn intricate patterns, as without them, the network would behave linearly.
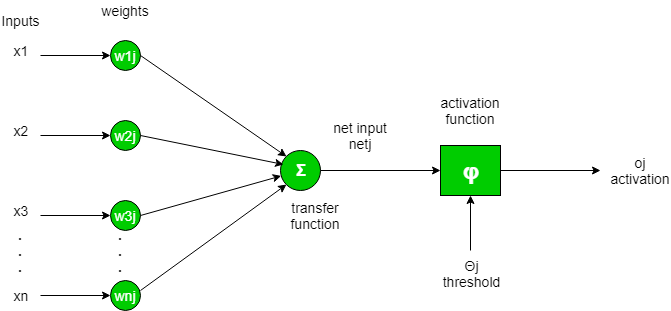
Common Activation Functions are:
-
Linear Activation: This is the simplest type. It just scales the input by a certain factor. Imagine it like stretching or compressing a spring. However, it's rarely used in deep learning because it doesn't add much complexity. Formula for linear activation is:
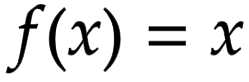
-
Step Activation: It's like a light switch. If the input is above a certain threshold, the neuron fires and gives an output of 1. Otherwise, it's inactive with an output of 0. It's not used very often either, as it's quite limited in what it can represent. Formula for Step activation is:
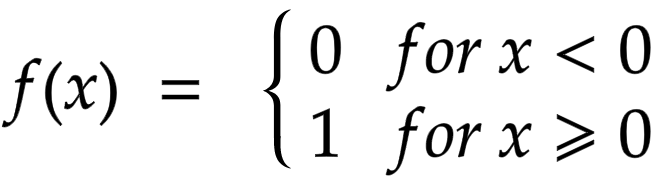
-
ReLU (Rectified Linear Unit) Activation: This is like turning on a light switch if the input is positive, otherwise, it's off. It's very popular because it helps the network learn complex patterns effectively and quickly. Formula for ReLU activation is:
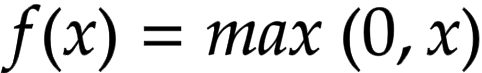
-
TanH (Hyperbolic Tangent) Activation: Similar to the sigmoid, but it squashes inputs to a range between -1 and 1. It's useful when you want to allow negative values in the output. Formula for TanH activation is:
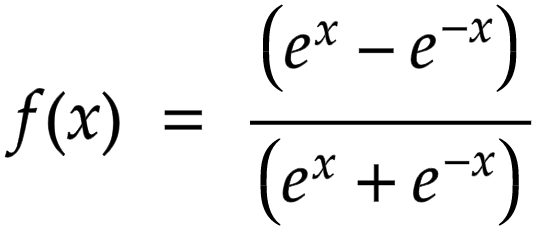
-
Sigmoid Activation Function: It is commonly used as an activation function in artificial neural networks, particularly in feedforward neural networks. This is because it allows the network to introduce non-linearity into the model, which allows the neural network to learn more complex decision boundaries. Formula for Sigmoid activation is:
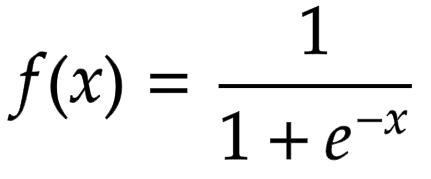
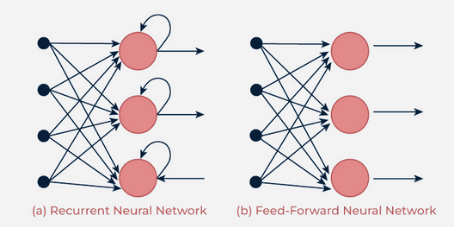
- Feedforward Neural Networks (FNN): FNNs are the simplest form of ANNs, where information flows in one direction—from the input layer to the output layer. They are effective for tasks like image and speech recognition.
- Recurrent Neural Networks (RNN): Unlike FNNs, RNNs have connections that form cycles, allowing them to retain information over time. This makes them suitable for sequential data processing, such as in natural language understanding and time-series analysis.
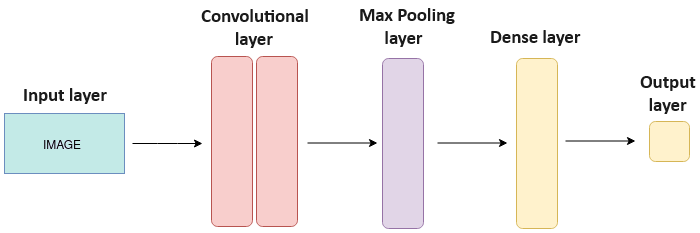
- Convolutional Neural Networks (CNNs): CNNs excel in tasks related to image recognition and computer vision. They leverage convolutional layers to automatically learn spatial hierarchies of features.
- Non-linearity : ANNs can model complex, non-linear relationships between inputs and outputs, making them suitable for tasks that involve intricate patterns and data relationships.
- Adaptability and Generalization : ANNs can adapt and learn from data, enabling them to generalize patterns and make predictions on new, unseen data.
- Parallel Processing : ANNs can process multiple inputs simultaneously, leveraging parallel computing capabilities and speeding up computation for certain tasks.
- Feature Learning : ANNs can automatically learn relevant features from the input data, reducing the need for manual feature engineering, which can be time-consuming and error-prone.
- Highly Expressive : Deep Neural Networks, a type of ANN, can learn hierarchical representations of data, allowing them to handle complex tasks like image and speech recognition.
- Wide Applicability : ANNs have found applications in various domains, such as computer vision, natural language processing, speech recognition, recommendation systems, and more.
- Black Box Nature : ANNs can be challenging to interpret, especially deep neural networks. Understanding how and why they arrive at specific conclusions can be difficult, leading to potential trust and transparency issues.
- Large Amount of Data and Computation : Training ANNs typically requires a large amount of labeled data and substantial computational power. Deep architectures can be computationally intensive and time-consuming to train.
- Overfitting : ANNs can be prone to overfitting, especially when the model is too complex relative to the available data. Overfitting occurs when the model performs well on the training data but poorly on new, unseen data.
- Hyperparameter Sensitivity : ANNs have many hyperparameters (e.g., learning rate, number of layers, neurons per layer), and tuning these hyperparameters can be a challenging and iterative process.
- Data Dependency : The performance of ANNs heavily relies on the quality and representativeness of the training data. Biased or noisy data can adversely affect model accuracy.
- Lack of Causality : ANNs often excel at pattern recognition but might not provide insights into causal relationships between variables, making them less suitable for certain scientific or causal inference tasks.
Common Activation Functions
Activation functions introduce non-linearity to neural networks. They help the network learn complex mappings between inputs and outputs.
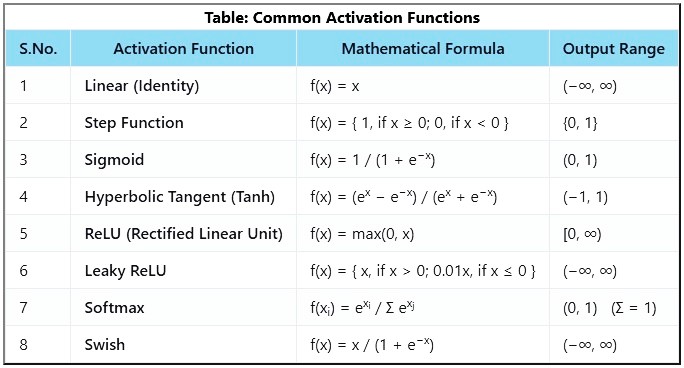
These function can significantly impact the network's training, convergence, and generalization capabilities. The appropriate function should be chosen based on the specific characteristics of your data and problem domain.
Types of Neural Networks:
Advantages of Artificial Neural Networks:
Disadvantages of Artificial Neural Networks: